Abstract
Deep neural networks are susceptible to attacks from adversarial patches in visual tasks, prompting researchers to develop various defense strategies. However, these traditional methods often perform poorly in dynamic 3D environments. This paper proposes a novel active perception-based object detection method that employs a cyclical mechanism combining perception and strategy modules to leverage environmental information in addressing adversarial patches in the 3D real world. Experimental results demonstrate that our approach significantly enhances the robustness of object detection models while maintaining high accuracy.
Introduction
Adversarial patches have become a significant threat to deep neural networks (DNNs) across a broad range of visual tasks. These meticulously crafted adversarial patches can be maliciously placed on objects within a scene, intended to cause erroneous model predictions in real-world 3D physical environments. Consequently, this poses safety risks or severe consequences in numerous security-critical applications such as authentication, autonomous driving, and security monitoring.
In response to these threats, various defense strategies have been developed to enhance the robustness of DNNs. Adversarial training is one effective countermeasure that incorporates adversarial examples into the training dataset. Additionally, input preprocessing techniques such as adversarial purification aim to eliminate these perturbations. Overall, these strategies primarily represent passive defenses; they mitigate the adversarial effects on uncertain monocular observations based on the adversary’s prior knowledge. However, passive defenses have inherent limitations. Firstly, they remain vulnerable to undiscovered or adaptive attacks that evolve to circumvent robustness, as they rely on preconceived assumptions about the adversary’s capabilities. Secondly, these strategies treat each static 2D image independently, without considering the intrinsic physical context and corresponding understanding of scenes and objects in the 3D domain, which may lead to suboptimal performance in real-world 3D physical environments.
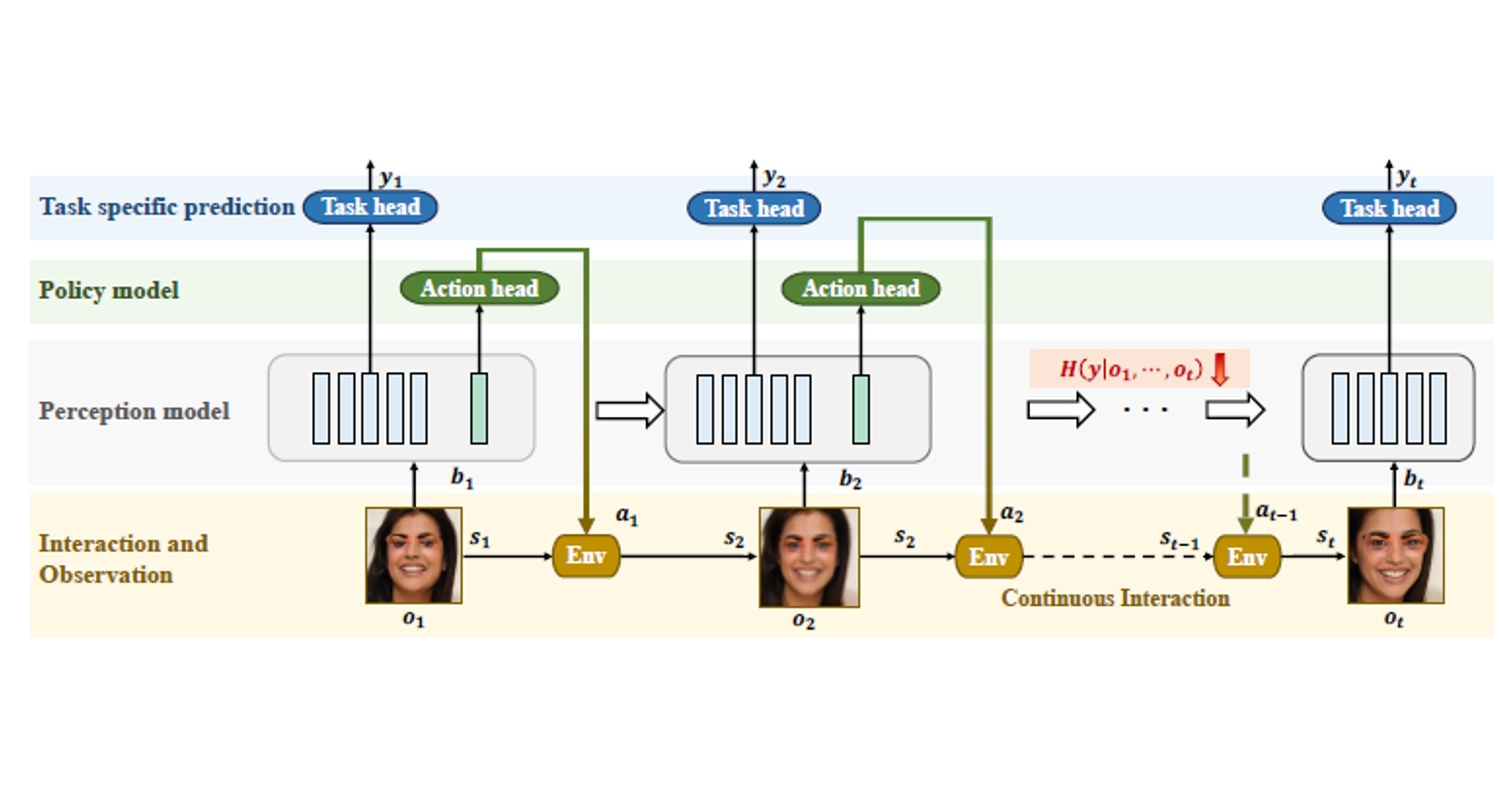
In contrast, human perception relies on a broad range of scene precedents and spatial reasoning to identify anomalies or discordant elements. Research indicates that even if these differences cause DNNs to err from a single viewpoint, human perception can easily recognize misaligned patches or objects in a 3D environment. Inspired by this, we introduce an active perception-based object detection method that actively integrates environmental context and shared scene attributes to address misaligned adversarial patches in 3D real-world settings. By implementing the two key functionalities of active vision, namely perception and motion, our approach consists of two main submodules: the perception model and the strategy model. The perception model continuously refines its understanding of the scene based on current and past observations, while the strategy model derives strategic actions from this understanding to more effectively collect observational data. These modules work in concert, enabling the system to continually enhance its understanding of the scene through active motion and iterative prediction, ultimately mitigating the harmful impact of adversarial patches. The overall framework is illustrated as shown in the figure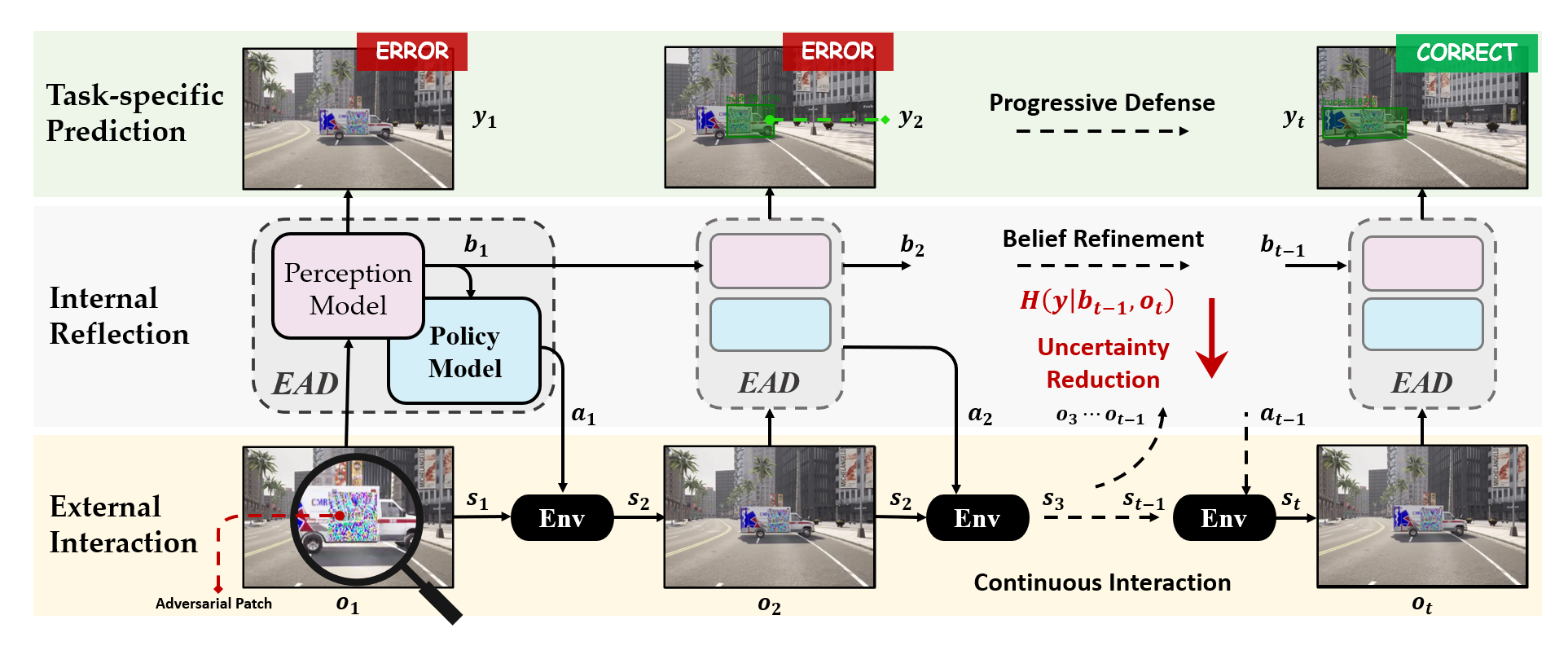
However, designing training for interaction-based models grounded in embodiment presents inherent challenges, as the policy and perception models are interconnected through complex probabilistic environmental dynamics. To address this issue, we adopted a deterministic and differentiable approximation of the environment, thereby bridging the gap between the two submodules and leveraging advancements in supervised learning.
Extensive experiments demonstrate that our proactive perception approach to object detection has several clear advantages over typical passive defenses. First, in terms of effectiveness, our method significantly surpasses the state-of-the-art defense mechanisms in defending against adversarial patches, achieving substantial progress in just a few steps. Notably, by providing informative guidance for recognizing target objects in dynamic 3D environments, it not only maintains but even enhances standard accuracy. Second, this design, which does not depend on specific attacks, exhibits excellent generalization capabilities across a wide range of previously unseen adversarial attacks, outperforming the latest defense strategies comprehensively, including patches created by various unseen adversarial attacks. Our contributions are as follows:
Model and Strategy Development: We developed a set of perception and decision-making models based on Transformers. These models utilize self-attention mechanisms to process and integrate image data across multiple time points. Through this approach, the model can capture instantaneous changes in the environment while optimizing the decision-making process via active exploration and multi-angle information acquisition, thereby significantly enhancing the system’s defensive capabilities in dynamic adversarial environments.
Construction of Differentiable Rendering Environment: Utilizing the latest EG3D model, we constructed a highly realistic differentiable rendering environment that not only supports precise visual outputs but can also simulate near-realistic visual effects. The introduction of this environment allows the model to train and test under conditions that closely resemble actual operations, thereby better adapting to and responding to the complexities of real-world scenarios.
Optimization Methods for Adversarial Patches: We propose a new strategy based on Expectation over Transformation (EoT) for optimizing adversarial patches. This method tests the effects of patches under varying physical conditions, enabling the creation of adversarial disturbances with high generalization abilities that demonstrate stronger adaptability and persistence in the physical world.
Active Perception Defense
In this chapter, we will explore a novel methodology that differs from traditional training methods based on static single-viewpoint data. This approach aims to improve model predictive performance by simulating the dynamic perception and cognitive processes of humans interacting with their environment. Additionally, to train and validate the effectiveness of the model, we construct a dynamic and differentiable rendering environment to simulate the real physical world. This allows the model to actively explore and gather information, fostering a deeper understanding of complex environments and significantly enhancing the model’s adaptability and robustness in practical applications, particularly in the face of adversarial patch attacks.
Active Perception Method
Inspired by the perceptual and learning mechanisms of the human brain, this study proposes a new dynamic exploration framework. The brain is proactive in constructing cognition of the environment, relying on the accumulation and integration of current and historical environmental observations, and subsequently taking action to explore and assimilate new information to strengthen its understanding and cognition of the environment. This method simulates the process of cognitive establishment, intending to achieve a more comprehensive understanding of the scene through active exploration of the model, thereby enhancing the performance and robustness of specific tasks such as target detection.
Specifically, in a given scene $ x \in X $, the model’s task is to collect observations $ o_0 … o_n \in O $ through a series of exploratory actions, thereby establishing cognition and understanding of the scene and solving specific tasks (this paper mainly focuses on target detection). This process can be modeled as a Markov Decision Process (MDP):
In this context, each specific scene $ x $ defines a particular state transition function $ T(s_{t+1}|s_t, a_t, x) $. Specifically, each state $ s_t $ not only includes the current observation perspective $ v_t $, but also contains all observations obtained prior to time step $ t $, denoted as $ o_0 … o_t $. At this point, the model can make predictions based on $ s_t $. Through this dynamic interactive exploration strategy, the model is capable of reacting not only to individual observation points but also integrating a series of observations to form profound insights into complex environments. This sharply contrasts with traditional static learning methods, which often lack proactive exploration mechanisms and the ability to adapt to dynamic changes in the environment. Moreover, in this manner, the model can more robustly identify and respond to potential threats when faced with diverse adversarial attacks, thereby enhancing overall defense performance.
Overall, the model is divided into two parts: the \textbf{decision model} and the \textbf{detection model}. The decision model $ \pi(\cdot; \phi) $ is parameterized by parameters $ \phi $, responsible for formulating the subsequent exploration strategy based on the sequence of observation data obtained up to the current moment, which can be formally represented as:
The detection model $ f(\cdot;\eta) $ is parameterized by the parameters $ \eta $, and aims to more accurately predict the annotations of a scene or image based on all the observational data accumulated thus far, formally expressed as:
In certain visual tasks such as classification or facial recognition, changes in perspective do not alter the labeling of the scene— for instance, regardless of the angle from which it is viewed, the true label of an apple remains “apple.” However, in tasks like object detection or instance segmentation, changes in perspective can significantly impact the labeling. This study focuses on object detection, aiming to enhance the labeling performance for the observation $ o_t $, particularly in terms of labeling accuracy in the presence of perspective changes.
Differentiable Rendering Environment
In the training of deep learning models, ensuring the differentiability of the loss function with respect to the model parameters is crucial. This is because the optimization process of the model—especially through the Stochastic Gradient Descent (SGD) method—relies on the ability to compute the gradient of the loss function at each parameter point. The calculation of the gradient depends on the backpropagation algorithm, which propagates the loss back through the computation graph, utilizing the chain rule to compute gradients layer by layer. If the loss function is not differentiable at certain parameter points, it becomes impossible to determine the gradient, leading to a loss of guidance for parameter updates during SGD. The foundational requirement for the implementation of backpropagation is that every node operation in the computation graph must be differentiable; any non-differentiable node may prevent gradients from propagating further in the network, thus interrupting the entire computation graph. Therefore, for effective learning and optimization of the model, selecting or designing a well-defined loss function that is differentiable with respect to the model parameters is fundamental. This ensures the existence of gradients and the feasibility of computation, which are key to achieving effective parameter updates and successful model training.
In traditional rendering environments, such as CARLA, although the scenes support complex graphics and physical simulations, the rendering process relies on GPU-accelerated graphics pipelines, which involve a large number of nonlinear operations, such as lighting, shadows, and reflections, that are typically non-differentiable. In contrast, EG3D (Explicit Generative 3D) is an advanced generative model designed to create high-quality three-dimensional content while supporting detailed two-dimensional rendering outputs. The main characteristic of this model is its ability to explicitly model and render objects in three-dimensional space, thus providing realistic visual effects while maintaining the differentiability of the rendering process. Based on this feature, we designed a novel rendering environment on the foundation of the EG3D model. This environment is capable of modifying the viewpoint based on actions, thereby providing the model with multi-view observation images. Simultaneously, its differentiability allows us to use the loss function from the object detection task to optimize the parameters of both the decision model and the detection model, ensuring the continuity and differentiability of the entire computation process, as illustrated in the computation graph of the model.
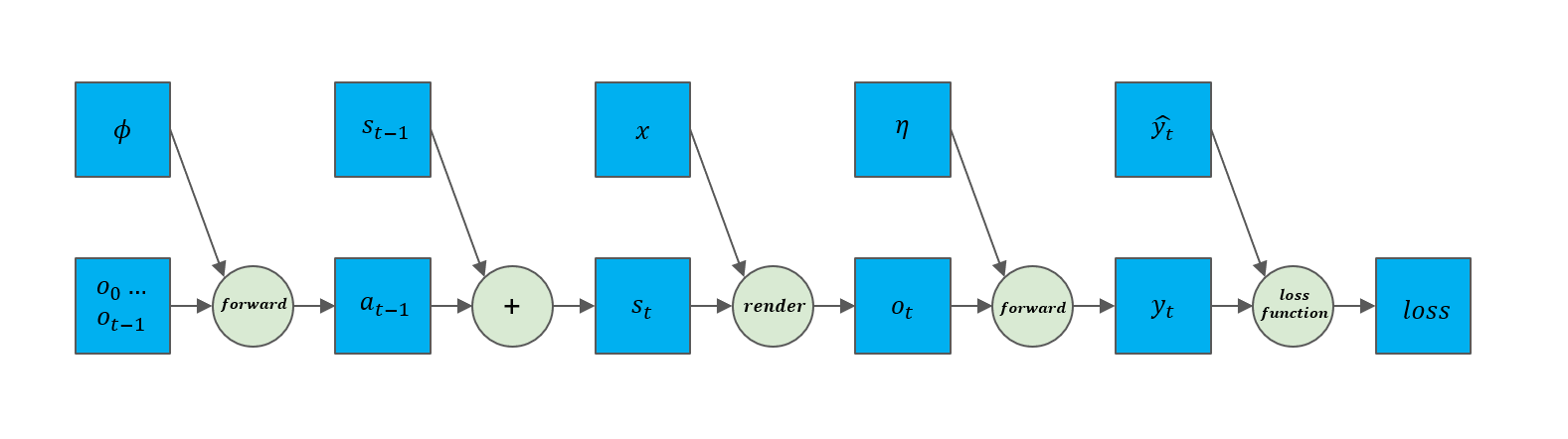
Specifically, we utilize the EG3D model pre-trained on the ShapeNet Cars dataset to generate multi-view images of vehicles. The vehicle scene $x$ is uniquely determined by the random seed $r$ of the latent representation that generates the vehicle, and the generated images have a resolution of $128 \times 128$. Meanwhile, we employ fixed camera intrinsic parameters and radial distance to control the observational camera’s movement on a fixed spherical surface, ensuring that the camera always points toward the position of the vehicle (i.e., the origin) and maintains a fixed radial rotation angle. Thus, the camera pose is uniquely determined by the observation angles $v$, namely the polar angle $ \theta $ and the azimuthal angle $ \varphi $. Through this setup, we construct a differentiable rendering function $\mathcal{R}(v, r)$, as illustrated below, which effectively supports the optimization of model performance from different observation angles.

Overall, we propose a deterministic environmental model suitable for our experimental environment:
Model Structure and Training
Model Structure In this experiment, we adopted the YOLOv5s architecture as the foundation for object detection. YOLOv5s is renowned for its ability to efficiently fuse features from multiple layers, a capability essential for detecting objects of various sizes. To enhance the model’s defensive ability against adversarial attacks on objects of different sizes, we specifically selected feature maps closer to the input layer to fully utilize the fine-grained features from the earlier layers. In this experiment, we used an input size of $(3 \times 128 \times 128)$, with a feature map size of $(64 \times 16 \times 16)$.
The Transformer architecture, with its self-attention mechanism, has demonstrated exceptional feature fusion capabilities in handling sequential data. Based on this, we introduced a variant of Transformer—BETR—in this experiment to implement feature fusion between multi-frame images. This approach aims to enable the model to understand scenes through multi-perspective observations, thereby enhancing the defense capability of the object detection model against adversarial attacks.
To balance the model’s parameter scale and computational efficiency, we flattened the last two dimensions of each feature map, forming 64 tokens, each with a length of 256. These tokens, along with the previously obtained feature maps, form a sequence of feature tokens, which are further processed through BETR for deep feature fusion. The fused feature map is then restored to its original shape and fed back into the YOLOv5s model to perform prediction tasks.
Additionally, to enable the model to actively adapt to the environment, we introduced learnable action tokens in this experiment. These action tokens are used to query the optimal viewpoint transformation strategy based on the current environmental state. Specifically, these action tokens are processed alongside the feature token sequence through BETR, after which a multi-layer perceptron (MLP) generates decision actions $a_t$ to guide the model in adjusting its observation perspective, thus optimizing detection performance. The specific model structure is illustrated in the accompanying figure.
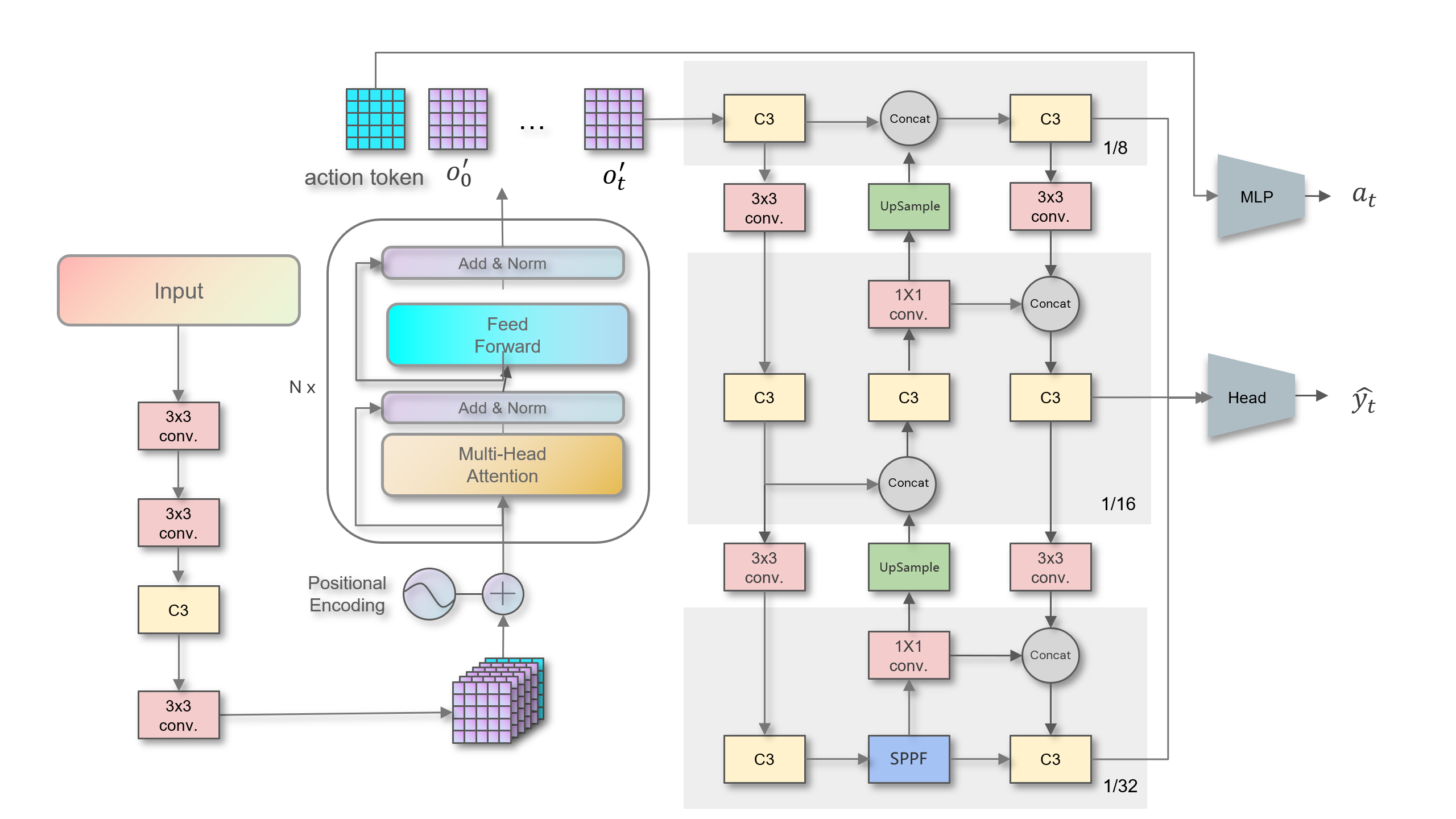
Model Training: As shown in computation graph, we create a connected computation graph between the policy and perception models to support the use of backpropagation, optimizing the parameters of the policy model $ \phi $ and the parameters of the detection model $ \eta $ simultaneously through stochastic gradient descent. To maximize training efficiency, we compute the loss and accumulate it as total loss after each prediction step in every training scenario, updating the model parameters only after the final step is completed. The algorithm described below outlines the overall training process.

Adversarial Patch Generation
The goal of this section is to construct adversarial patches for detection, so as to deceive the YOLOv5s model in the rendering environment we have developed, thereby verifying the effectiveness of detection defense methods. For our rendering environment, it is crucial to implement a patch application function $A$ that better simulates patches in the physical world. Given the camera intrinsic parameters $K$ used in the rendering environment, the function attaches the patch $p$ to the output image $o$ from the renderer, adhering to the physical laws of the real world, which can be formally expressed as:
Our rendering environment primarily handles angular changes; therefore, when implementing the application function $A$, we mainly consider perspective transformations. A key task in applying the perspective transformation is determining the pixel positions of the vertices of the patch after the transformation on the 2D image.
First, we consider rotational transformations. Establishing a coordinate system with the camera as the origin, since the camera always points toward the vehicle’s location, the transformation caused by camera rotation is equivalent to the rotation of the patch around its center. Assuming the origin of the coordinate system is at the patch center, the transformation matrix for its world coordinates concerning the polar angle $ \theta $ and azimuthal angle $ \varphi $ can be represented as:
Next, to determine the pixel positions of the vertices of the patch on the 2D image after the fixed transformation, we utilize a 3D patch projection process similar to that of Zhu et al. Taking the camera as the origin of the world coordinate system, this transformation can be accomplished through two inversely reciprocal translation transformations. Let the world coordinates of the patch center be $p = (x_p, y_p, z_p)$, and the translation transformation matrix can be expressed as:
At this point, we can construct the projection matrix that maps world coordinates to pixel positions on the image:
where
Given patch $p$, we determine its world coordinates before and after transformation, and after finding its pixel position in the image using the aforementioned projection matrix, we apply a perspective transformation to $p$ using the interface provided by Torchvision, as shown in the figure below:

This operation is differentiable, allowing us to optimize the adversarial patch to deceive the YOLOv5 model. It can be formally represented as:
Instead of using the YOLO loss function directly as the loss $\mathcal{L}$ in the above expression, we adopt a similar attack strategy that maximizes the objective confidence loss of the anchor boxes, with the aim of rendering the detected object “invisible” :
Experiment
Since our method did not use adversarial data during the training phase, we adopted several purification-based defense strategies as comparative baselines, as shown in Table 4-3. Under the unprotected condition, the model’s performance was at its lowest, indicating that the model is extremely sensitive to adversarial attacks without any defense measures. For example, under an 8% patch size without defense, the mAP for MIM and EoT attacks was only 30.4% and 28.5%, respectively, demonstrating a significant drop in the model’s performance when subjected to adversarial attacks.
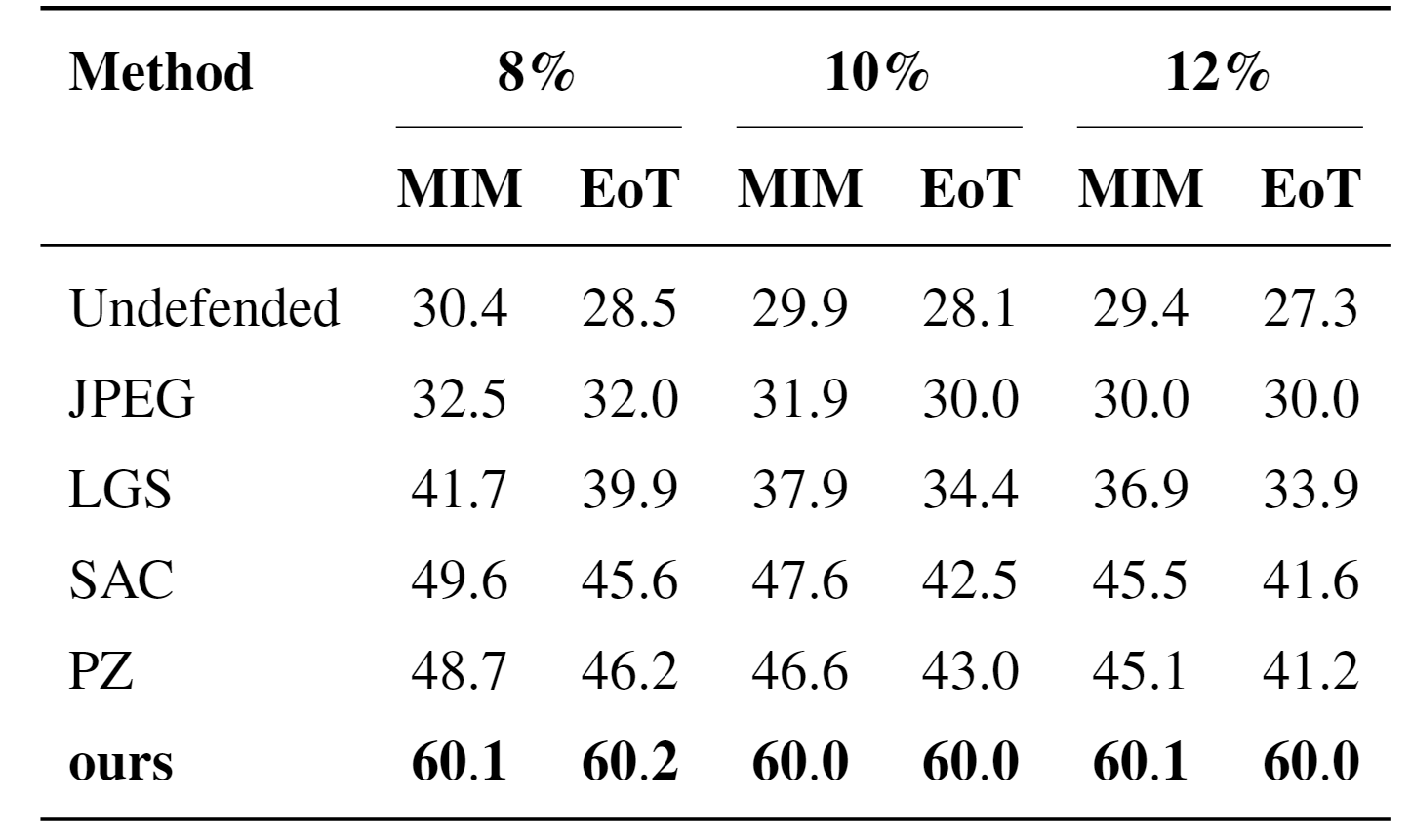
JPEG and LGS provided a certain degree of defensive effect, but they were still insufficient to effectively resist advanced adversarial attacks. SAC and PZ exhibited better defensive performance, particularly SAC, which improved the model’s defense capability against adversarial attacks to some extent. However, these methods still could not compete with the approach presented in this paper, possibly because our method utilizes more complex and advanced strategies to enhance the model’s robustness. Specifically, our method maintained an mAP50-95 of over 60% across all tested patch sizes and attack types, which is significantly higher than that of other methods. At the same time, we also observed that our method demonstrated significantly better performance than other defense strategies under both normal scenarios and adversarial attack environments. This further underscores the exceptional generalization ability of our method in handling unknown adversarial attacks.
From the perspective of information entropy, traditional defense strategies typically rely on image data from a single viewpoint, which limits the amount of information the model can utilize. In adversarial environments, attackers often deceive the model through carefully designed perturbations, which may be difficult to defend against from a specific observation angle. However, when the model can receive inputs from multiple angles and integrate multi-angle observational information, deceiving the model becomes exceedingly difficult. Thus, multi-angle information input significantly enhances the model’s perception capabilities against attack perturbations, thereby reducing the success rate of adversarial samples deceiving the model from different perspectives.
Additionally, the information provided by multiple viewpoints is not limited to enhancing the model’s defense capabilities against known attacks, but also improves the model’s adaptability to unknown attacks. Due to the increase in information entropy, the model can utilize the received information more effectively for accurate decision-making when facing diverse attack strategies, thus enhancing the overall system robustness. Therefore, from this perspective, the defense strategy proposed in this paper effectively capitalizes on the increased amount of information obtained from multiple viewpoints, which not only improves the model’s detection capabilities but also significantly enhances the model’s safety and reliability in adversarial environments. These experimental results thoroughly demonstrate the effectiveness of our method in enhancing the adversarial defense capabilities of the target detection model.
Discussion
In this study, we developed a novel active defense strategy aimed at mitigating and countering the threats posed by adversarial patches. Our approach differs from traditional defense strategies, which often rely on static analysis from a single perspective. Instead, our strategy dynamically explores the environment, actively collecting comprehensive information about the targets, significantly enhancing the system’s robustness and security. We validated this strategy in multiple experiments, demonstrating how it effectively strengthens defense capabilities without requiring prior knowledge of the adversary, and proved its remarkable generalization ability across various application scenarios. Additionally, this strategy successfully improved the model’s recognition accuracy in non-adversarial environments, indicating that it can not only defend against malicious attacks but also enhance model performance in everyday applications.
Furthermore, this research innovatively introduced the technique of differentiable perspective transformation, which provides crucial technical support for creating adversarial patches. By simulating various transformations that may occur in the physical world, we were able to design more challenging testing scenarios, thus effectively enhancing the defense model’s response capability. The adoption of this technology not only opens new perspectives for the study of adversarial patches but also propels overall advancements in the field of adversarial machine learning.
However, despite the numerous advantages of our strategy, some challenges were encountered during practical application. The newly introduced perception and decision-making models increased the system’s computational demands and resource consumption, which are comparable in scale and cost to traditional adversarial training. Therefore, to apply this method to practical embodied AI systems, such as autonomous vehicles, drones, or service robots, extensive testing and optimization must be conducted in realistic simulated environments or real-world conditions to validate its actual effectiveness and practicality.
Moreover, although our experimental design strives to comprehensively simulate various conditions of the physical world, certain complex factors from real life remain uncovered, such as changing lighting conditions, the complexity of environmental textures, and potential errors from camera sensors. The absence of these factors may affect the method’s generalization ability and real-world performance. To comprehensively assess the effectiveness of this strategy and ensure its efficient operation in diverse environments, future research could leverage 3D printing technology to create more varied testing environments, as well as conduct more in-depth experiments and validations within more advanced simulation systems. These efforts will help us better understand the potential applications and limitations of this method, providing guidance for future optimization and practical deployment, thereby ensuring that the strategy achieves optimal performance in the real world.