Introduction
Syntax analysis, or parsing, is a key phase in compiler construction, used to determine the grammatical structure of source code. Traditional methods like LL(1) parsing and recursive descent parsing are often implemented in low-level languages such as C for better performance. However, writing syntax analysis programs manually is time-consuming and error-prone due to the repetitive nature of grammar-specific code.
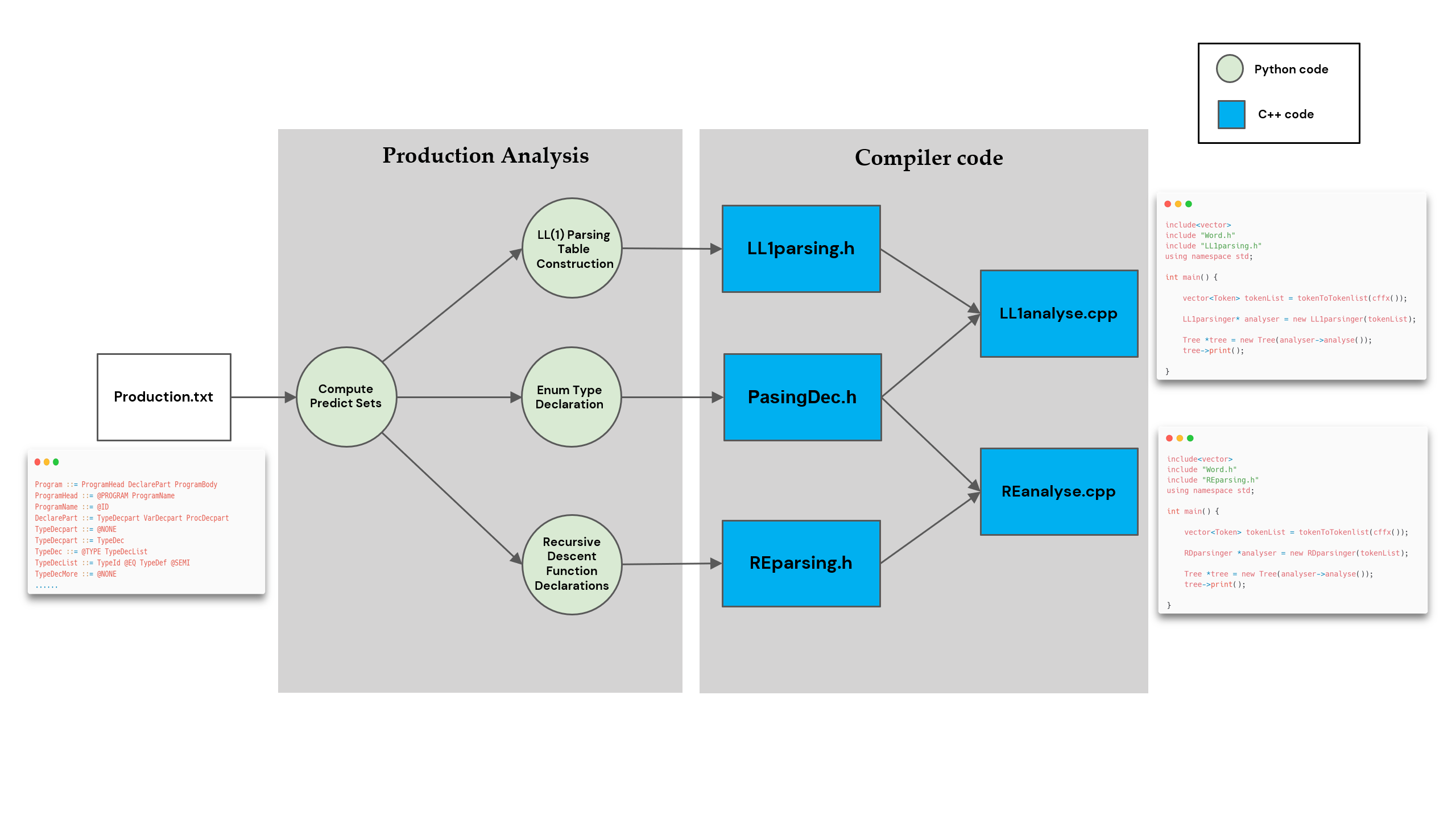
To improve efficiency and adaptability, especially when creating compilers for new languages or adapting to changes in existing languages, we developed a tool that automatically generates syntax analysis programs in C for any programming language. This generator increases code reuse, reduces manual effort, and maintains high execution efficiency. The overall framework of our solution is shown in Overall Framework Figure.
Key contributions of this work are summarized as follows:
Universal Tool Development: Python scripts were used to automate the generation of syntax analyzer code, significantly reducing manual coding efforts. A universal C language syntax analysis tool was created, capable of taking any language’s production rules as input to generate recursive descent and LL(1) syntax analysis programs, facilitating compiler development across languages.
Automated Predict Set Calculation: Python scripts were implemented to automatically compute predict sets from syntax production text, eliminating manual calculations and greatly improving efficiency and accuracy.
Error Correction and Validation: Errors in the textbook’s predict sets for SNL language production rules were identified and corrected, enhancing analysis accuracy and providing a solid foundation for further syntax analysis.
Production Analysis
The foundation of syntax analysis is grammar rules, which are generative for a specific language. All methods of syntax analysis are based on these rules. Thus, the main task of SNL syntax analysis is to clearly define the production rules of the SNL language. To facilitate future work, we have digitized all 112 production rules of the SNL language into a txt file using image text recognition. We replaced intermediate symbols with the corresponding strings as defined in the textbook and added an @ symbol in front of all terminal symbols to distinguish them from non-terminal symbols. Below are some documents of production rules and the symbol correspondence table:
1 | Program ::= ProgramHead DeclarePart ProgramBody |
The grammar of SNL is an LL(1) grammar, which means that for each non-terminal, you can determine which production to use for derivation by looking at the next token in the input token sequence, and the method of derivation is unique. The foundation for this derivation is calculating the predict set for each production’s right side. Therefore, we implemented a predict set calculation algorithm based on production text in Python and used it to solve the predict sets for each production in the SNL language. In the end, we compared our results with the predict sets in the textbook and pointed out a few errors in the textbook after verification.
Generation of declare code
In the implementation of grammar analysis code, considering that both LL(1) parsing and recursive descent parsing use the same terminal and non-terminal enumerations, as well as similar tree node declarations, we will declare all the necessary declarations related to the parsing stage in the “PasingDec.h” header file. This approach aims to facilitate code maintenance, reduce code duplication, and improve code readability and reusability, making it available for both recursive descent analysis and LL1 parsing. The call relationship is as follows:
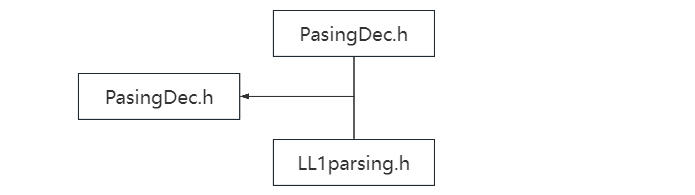
This header file includes all the necessary declarations involved in the syntax analysis phase, and its internal structure is as follows:
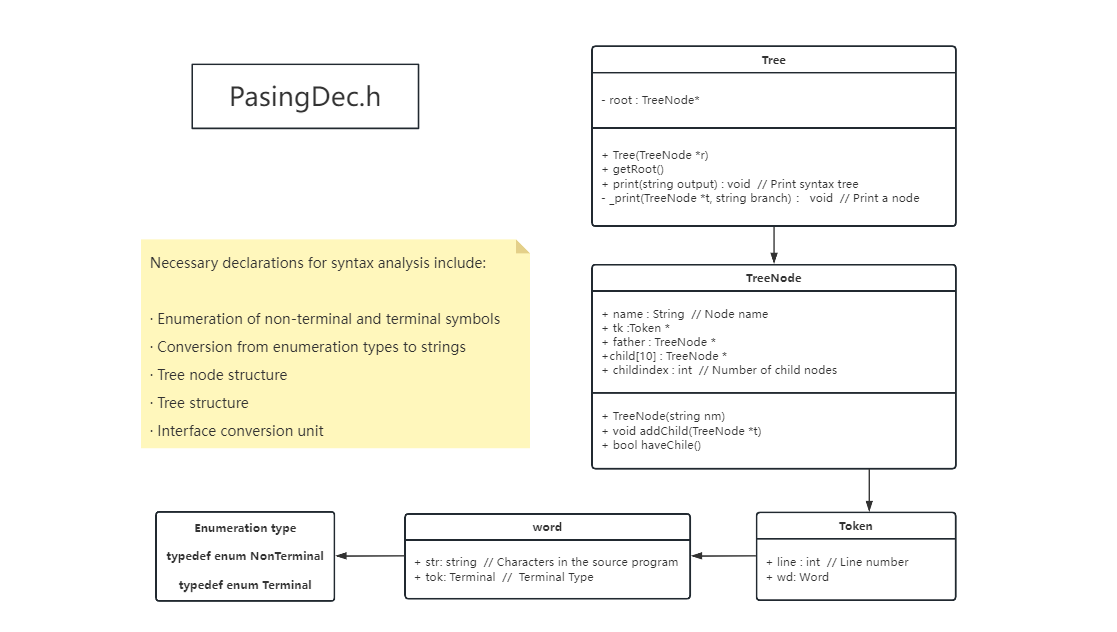
The enumeration of terminal and non-terminal symbols, as well as the conversion function from enumeration types to strings, are all automatically generated by Python code.
To achieve automatic code generation, we simplified the structure of the syntax analysis tree nodes, keeping only the information necessary for semantic analysis.
When specifically writing program code to implement the two types of syntax analysis, we chose an object-oriented programming approach, which significantly enhanced the encapsulation and readability of the syntax analysis code. At the same time, we fully leveraged the advantages of the Python language to create a tool that automatically generates semantic analysis code in C language. We improved its versatility so that it can accept production sets from any programming language and automatically generate the corresponding C language recursive descent semantic analysis code and LL1 semantic analysis code, reducing workload while improving the uniformity and accuracy of the code writing.
Generation of LL(1) Parsing Code
In LL(1) syntax analysis, a top-down parsing method is used, starting from the initial non-terminal symbol and gradually deriving program code that conforms to the grammar rules. This analysis method is characterized by its simplicity and efficiency, which can effectively detect syntax errors. When implementing the semantic analysis code for this method, various stacks and a specialized data structure, namely the node structure of the symbol stack, are needed, as well as the structure and LL(1) syntax analyzer outlined below.
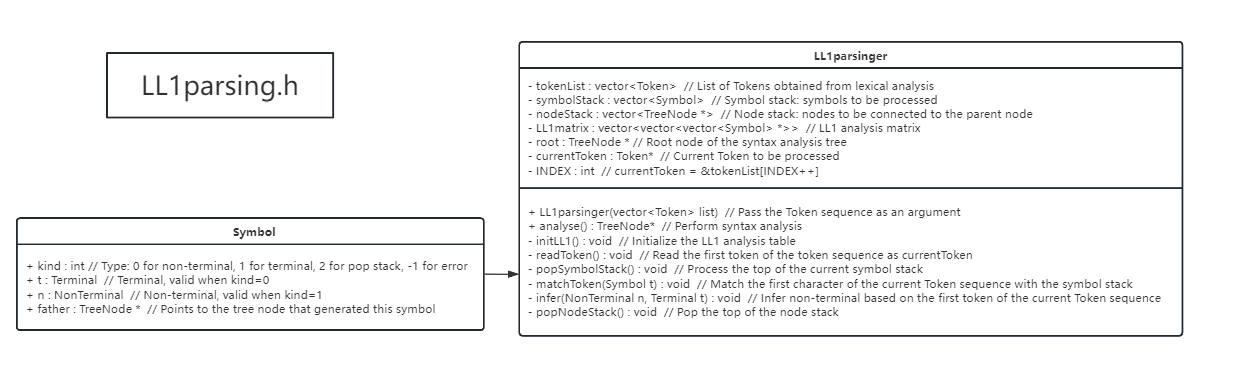
The key to implementing LL(1) syntax analysis lies in the initialization of the LL(1) parse table. This involves filling in the corresponding positions in the matrix with the symbols from the production rules of the SNL language grammar and their predict sets in order. Since different positions in the matrix can correspond to the same production rule and there are many repetitions, to save space in the heap, we use the pointer to the symbol sequence of a production as the content to fill multiple repeated positions in the parse matrix. We also use the same data structure as the elements in the symbol stack. This way, when we need to derive a non-terminal symbol at the top of the symbol stack, we simply refer to the LL(1) parse table, look up the corresponding symbol sequence, and push it onto the stack, which simplifies the analysis process.
Additionally, in writing this part of the code, there was a lot of redundant and repetitive work. We still utilize Python to automatically generate the initialization code for the LL(1) parse table. The overall idea is to generate a vector of symbols based on the structure of the right-hand side of the production rules, and then fill in the pointer to the symbol vector in the corresponding positions of the matrix according to the left-hand side of the production rule and its predict set. For instance, we generate the following initialization code for the LL(1) parse table based on the first production rule.
1 | // Generate symbol sequence vector |
When performing LL(1) syntax analysis, you just keep processing the top of the symbol stack. If it’s a non-terminal symbol, you derive it according to the parsing table. If it’s a terminal symbol, you match it with the input. Ultimately, whether the syntax analysis is successful relies on whether the entire symbol sequence is processed and the symbol stack is empty.
On this basis, to standardize the structure of the syntax tree and ensure that nodes with no child nodes after derivation aren’t connected in the syntax analysis tree, we use a node stack to store nodes that haven’t fully generated their child nodes. When popping from the symbol stack (“popping a symbol”), we also pop the top node from the node stack and determine whether it should be added to the syntax analysis tree.
Generation of recursive descent parsing code
The recursive descent parser starts analyzing the grammar from the highest level and works its way down step by step. During the analysis, if the current symbol is a non-terminal, it recursively calls the corresponding subroutine for that non-terminal; if the current symbol is a terminal, it matches the symbol, generates the corresponding node, connects it to the syntax tree, and moves the input pointer to the next symbol. In each handling function for a non-terminal, it selects the appropriate processing method based on the Predict set of one or more of its productions. This is how our recursive descent parser is structured:

When implementing the syntax analysis program for this method, the key is to write handlers for each non-terminal symbol, allowing the syntax analysis to be completed through a single comprehensive recursive call. Although this syntax analysis method is logically simple, it requires a substantial amount of coding and follows certain patterns. Therefore, we still use Python code to automatically generate handlers for all non-terminal symbols, with the general approach being:
Based on all the production rules that have the non-terminal as the left-hand side and their corresponding Predict sets, we match terminal symbols or call non-terminal procedures in the order of the production’s right-hand side, and throw an error if we can’t select a production.
To avoid conflicts between function name identifiers and enum type identifiers, we name functions using “_non-terminal name” and strictly follow the predict set for derivation. Even if a non-terminal has only one production, we still check whether the head of the token sequence to be processed belongs to its predict set, making the analysis process more rigorous. For example, the handler for the non-terminal Program is:
1 | TreeNode *RDparsinger::_Program() |
Result
Starting from the production rules, we solved the predict sets for each production in the syntax analysis of the SNL language. We implemented two object-oriented, highly readable, and uniformly structured syntax analyzers. During this process, we used Python code to simplify the workload, ultimately achieving the transformation from:
800 lines of C code + 250 lines of Python code -> 2500 lines of syntax analysis program (C code).
More importantly, we developed a general-purpose C language syntax analysis program generator. This program takes a set of production rules for a specific programming language as input and automatically generates the corresponding recursive descent syntax analysis program and LL(1) syntax analysis program.