强化学习
reinforcement learning(RL)讨论的问题是智能体(agent)如何在复杂、不确定的环境(environment)中最大化它能获得的奖励。
深度强化学习
深度强化学习 = 深度学习 + 强化学习 (类比于传统的计算机视觉和深度计算机视觉)
与监督学习的区别
没有非常强的监督者(supervisor),只有奖励信号(reward signal),并且奖励信号是延迟的
智能体获得自己能力的过程,其实是不断地试错探索(trial-and-error exploration)的过程。
探索 (exploration) 和 利用(exploitation) 是强化学习里面非常核心的问题。
监督学习算法的上限(upper bound)就是人类的表现
一些名词
预演(rollout)是指我们从当前帧对动作进行采样,生成很多局游戏。
轨迹(trajectory)是当前帧以及它采取的策略,即状态和动作的序列:$ τ=(s_0,a_0,s_1,a_1,…) $
一场游戏称为一个回合(episode)或者试验(trial)
决策序列
奖励:是由环境给的一种标量的反馈信号(scalar feedback signal)。在棋类游戏中,只有最后才会获得,强化学习里面一个重要的课题就是近期奖励和远期奖励的权衡 (trade-off)。
历史是观测、动作、奖励的序列:$H_t = o_1, a_1, r_1, …, o_t, a_t, r_t$
智能体如何采取当前动作会依赖于它之前得到的历史:$S_t = f(H_t)$
状态是对世界的完整描述,不会隐藏世界的信息。
观测是对状态的部分描述。
马尔可夫决策过程
环境有自己的状态更新函数$s_t^e=f^e(H_t)$,智能体的内部也有一个更新函数$s_t^a=f^a(H_t)$,当智能体能够观察到环境的所有状态时,我们称这个环 境是完全可观测的(fully observed)。在这种情况下面,强化学习通常被建模成一个Markov decision process(MDP)的问题。
部分可观测马尔可夫决策过程
partially observable Markov decision process (POMD) 具有马尔可夫性质,但是假设智能体无法感知环境的状态,只能知道部分观测值。可以用一个七元组描述:$(S, A, T, R, Ω, O, γ)$,其中 S 表示状态空间,为隐变量,A 为动作空间,T(s′∣s,a) 为状态转移概率,R 为奖励函数,Ω(o∣s,a) 为观测概率,O 为观测空间,γ 为折扣系数。
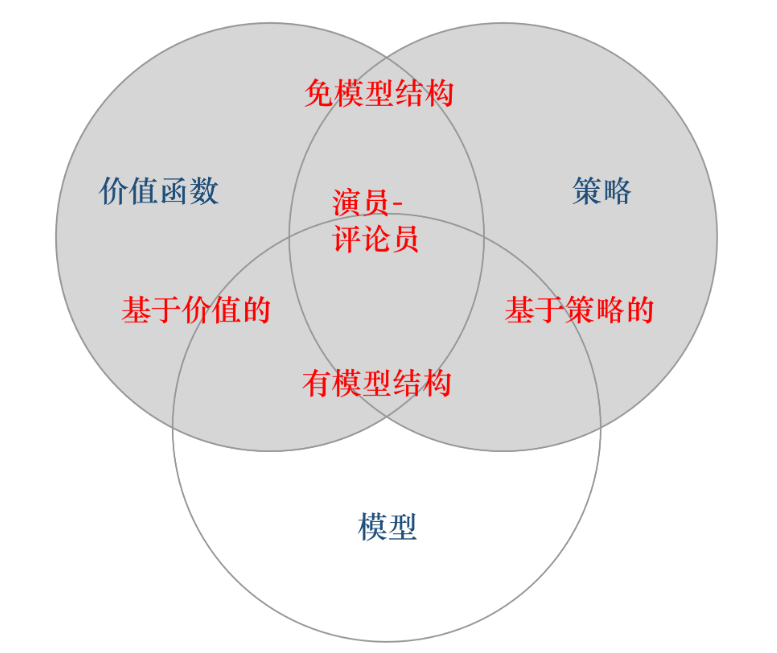
智能体
- 策略(policy):智能体会用策略来选取下一步的动作。
- 价值函数(value function):在某个策略下,从一个给定状态开始,智能体期望获得的累积未来奖励。
- 模型(model)。模型表示智能体对环境的状态进行理解,预测了“如果我做这个行动,会发生什么?”。
策略
随机性策略(stochastic policy): π 函数:$\pi(a|s)=p\left(a_t=a|s_t=s\right)$,给定状态,输出执行各种动作的概率。
确定性策略(deterministic policy):智能体直接采取最有可能的动作,$a^=\arg\max_a\pi(a\mid s)$,采用确定性策略的智能体总是对同样的状态采取相同的动作,这会导致它的策略*很容易被对手预测
价值函数
价值函数的值是对采取某个策略对未来奖励的预测,我们用它来评估状态的好坏。 里面有一个折扣因子(discount factor)。
G收益:一个特定决策序列某个时间步之后的长期收益
V函数:在状态 s 下并遵循特定策略的期望回报:
其中$\mathbb{E}_\pi$是指求概率平均(期望值),这个期望并不好求,因为穷举所有可能的决策序列并不显示
Q函数:表示在状态 s 下采取行动 a 并遵循特定策略的期望回报:
这个函数指定了当前步所采取的动作,而之后的动作依然根据策略$\pi$,所以$\pi$不可省略
模型
智能体对环境的模拟,它由两个部分组成:
- 状态转移概率
- 奖励函数
通常不是通过学习得到的,而是预先定义好的。除了环境给出的真实奖励,有些奖励也由人工设定或蒙特卡洛。
分类
学习 vs 规划
学习:学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型
规划:寻找最优解
探索 vs 利用
K-臂赌博机:有 K 个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币(对赌徒未知)。赌徒的目标是通过一定的策略最大化自己的奖励,即获得最多的硬币。
仅探索(exploration-only)法:想要知道每个臂的吐币概率,将所有的尝试机会平均分配给每个摇臂,最后以每个摇臂各自的平均吐币概率作为其奖励期望的近似估计。
仅利用(exploitation-only)法:按下目前最优的(即到目前为止平均奖励最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。
事实上,因为尝试次数(总投币数)有限,加强了一方则自然会削弱另一方,这就是强化学习所面临的探索-利用窘境(exploration-exploitation dilemma),想要累积奖励最大,则必须在探索与利用之间达成较好的折中。