前言
该项目是本人在编译原理课设计中的作业项目,本人负责部分为语法分析部分,该篇文章简要说明了整个语法分析部分的实现方案。
前期准备工作
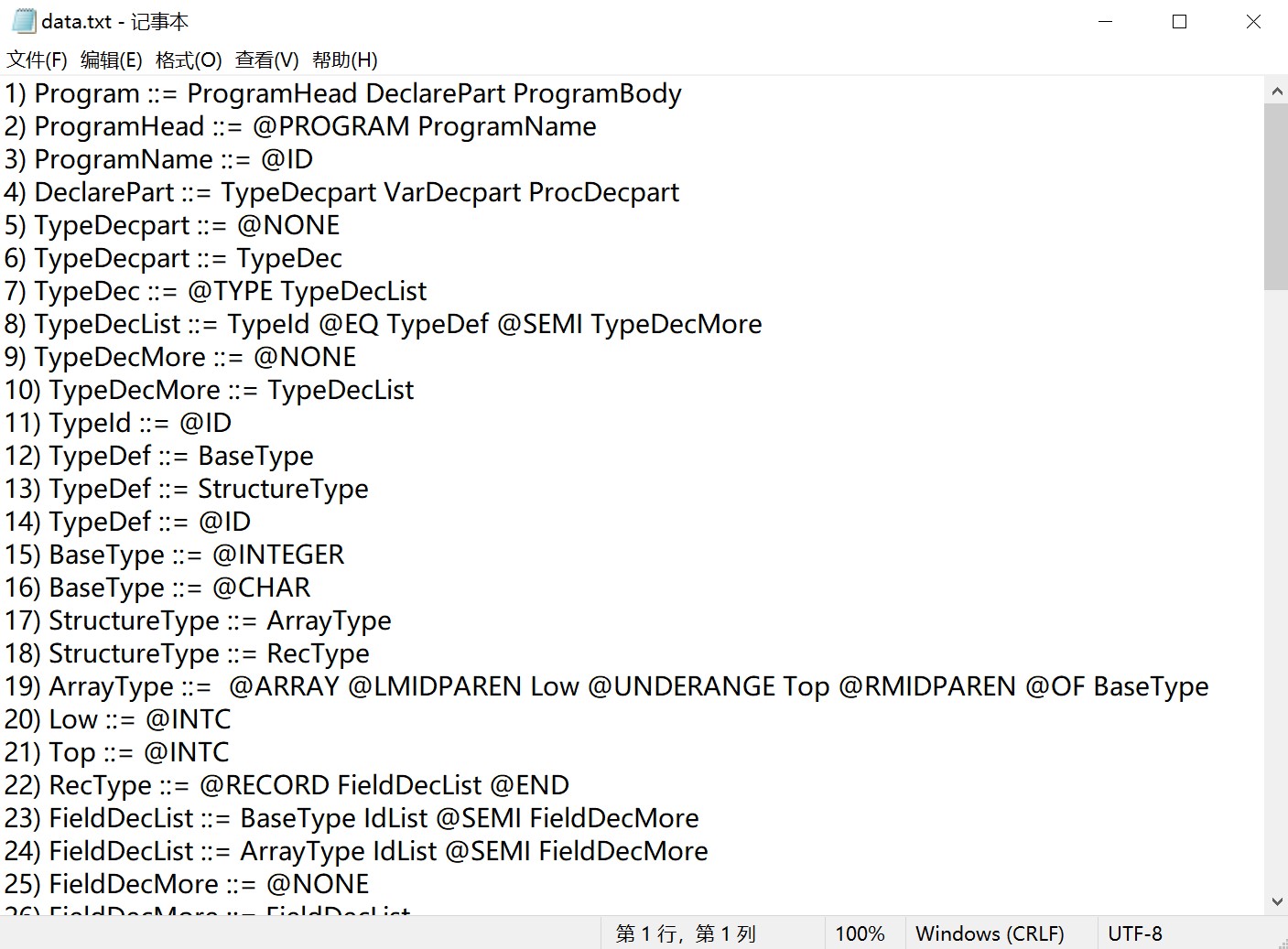
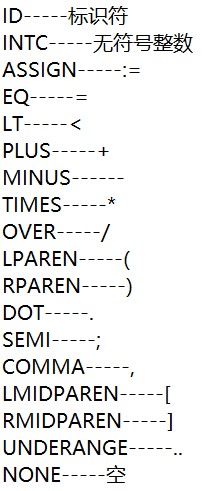
语法分析的基础是语法规则,即针对一门特定语言的产生式,所有语法分析的方法都要基于其进行。因此,进行SNL语法分析的主要任务是明确SNL语言的产生式,为方便后续工作的进行,我们将SNL语言的所有产生式(共112条),通过图片文字识别,以纯文本形式录入到了txt文件中,其中,符号形式的中级符被我们 按照教材上的定义,替换成了相应的字符串,并在所有 终极符前添加了@符号以和非终极符进行区分,部分产生式文档及符号对照表如下:
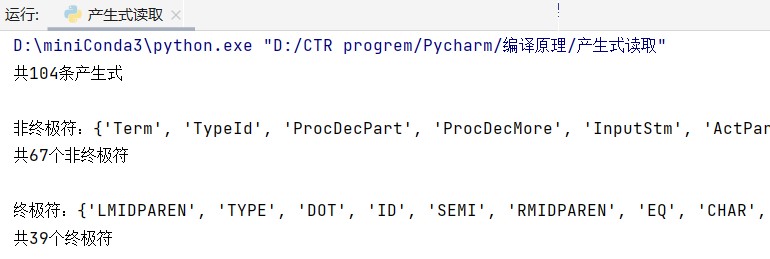
针对该txt文件,我们使用Python代码 读取其所有产生式,并统计了统计符合非终结符的个数,结果如下:
SNL的语法文法为LL1文法,即对于每个非终结符,都可以通过查看输入Token序列的下一个Token来确定使用哪个产生式进行推导,且推导方式唯一。而实现这种推导的基础是计算每个产生式右部的predict集。因此我们使用 Python语言实现了基于产生式文本的predict集求解算法,并用其对SNL语言各产生式的predict集进行求解,最终与教材中的predict集进行对比,经核对后指出了教材中的几处错误:

相关声明
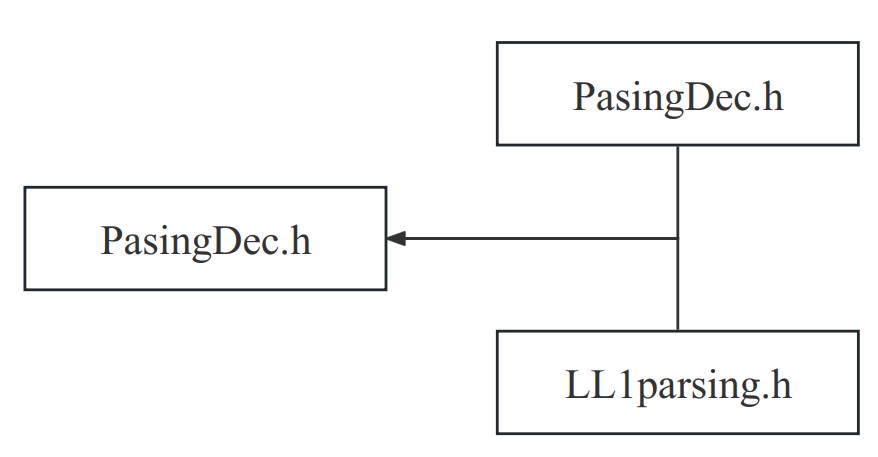
在语法分析的代码实现时,考虑到LL(1)语法分析和递归下降语法分析使用相同的终极符、非终极符枚举类型声明,相同的树结点等声明,为方便代码维护、减少代码重复、提高代码可读性与复用性,我们将在语法分析阶段所涉及的必要声明都声明在“PasingDec.h”头文件中,供递归下降共递归下降分析和LL1语法分析使用,其调用关系如下:
在该头文件中包含了,语法分析阶段所涉及的所有必要声明,其内部结构如下:
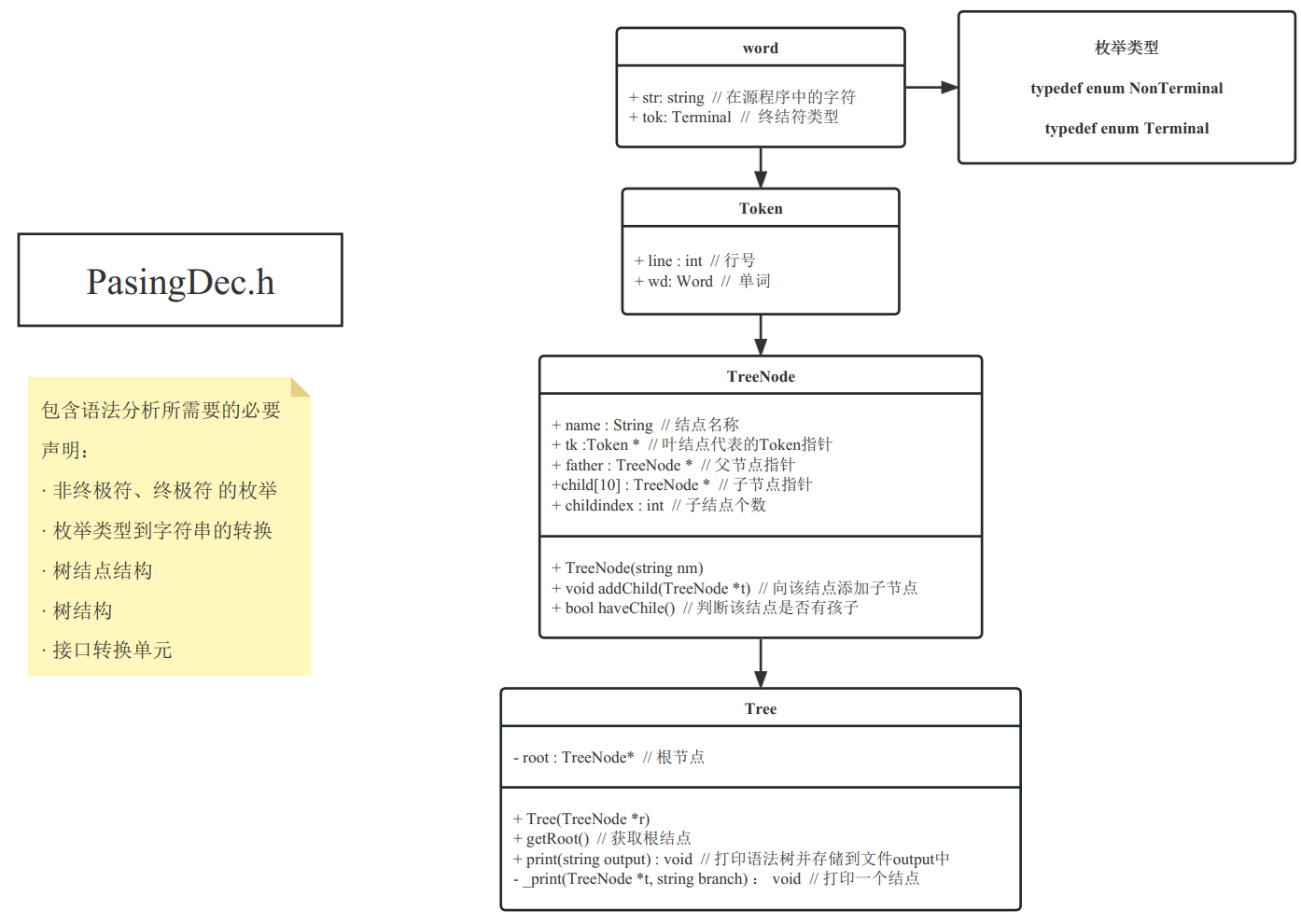
其中终极符和非终结符的枚举,及枚举类型到字符串的转换函数,均由Python代码自动生成。
为实现代码自动生成,我们简化了语法分析树结点的结构,仅保留了足够满足语义分析的信息。
在具体编写程序代码实现两种语法分析时,我们选择采用面向对象的编程方式,极大地提高语法分析部分代码的封闭性、可读性。同时,我们充分利用Python语言的优势,编写了自动生成语义分析部分c语言代码的工具,并完善了其通用性,使其可以接受任何一门语言的产生式集合,自动生成相应的c语言递归下降语义分析代码和LL1 语义分析代码,在减小工作量的同时,提高了代码编写的统一性与准确性。
LL(1)语法分析
LL(1)语法分析采用自顶向下的分析方法,即从最开始的非终结符开始,逐步推导出符合语法规则的程序代码,这种分析方法具有简单、高效的特点,可以有效地检测语法错误。在实现该种方式的语义分析代码时 需要用到多种栈及一种专用的数据结构,即符号栈的结点结构,其结构及LL1语法分析器如下:
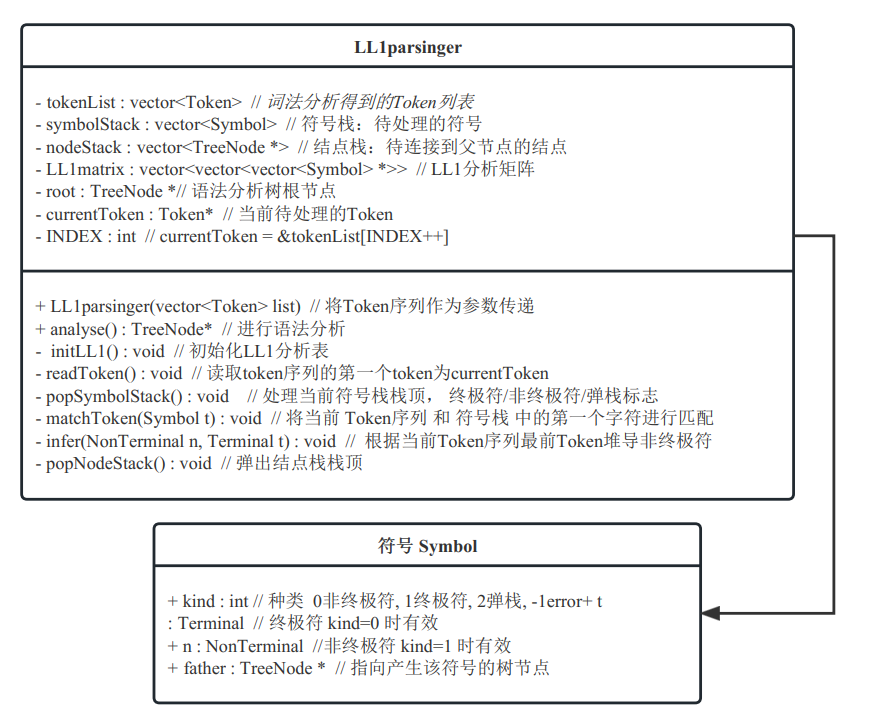
其中,实现LL(1)语法分析的关键为LL(1)分析矩阵的初始化工作,即根据SNL语言语法的产生式及其predict集,将产生式中的各个符号按顺序填写到矩阵的对应位置中,由于矩阵的不同位置可能对应相同的产生式,且存在大量重复,为节约堆区空间,在构建一个产生式的符号序列之后,我们将该序列的指针作为内容填写到分析矩阵中的多个重复位置,并且使用了与符号栈元素相同的数据结构,使得在对符号栈栈顶非终极符进行推导时,只需按照LL(1)分析矩阵,查找对应符号序列,直接压入栈中即可,简化了分析过程。
并且,在该部分代码的编写中 存在大量冗余重复的工作,我们仍然使用Python自动生成LL(1)分析矩阵的初始化代码。其整体思路为,按照产生式右部结构生成符号序列Vector,按照产生式左部及其predict集将符号向量指针填写到矩阵对应位置,如根据第一条产生式生成如下LL(1)分析矩阵初始化代码:

进行LL(1)语法分析时,只需不断处理符号栈顶,如果是非终结符 则按照分析矩阵进行推导 如果中意符则进行符号匹配,最终以是否符号序列 全部处理完成且符号占为空 作为语法分析是否成功的依据。
在此基础上,为规范语法树结构,使得推导后无子节点的节点 不会连接在语法分析树中,最终使得所有叶结点均为终极符,我们使用节点栈存储其子节点未全部生成的节点,在弹出符号栈“弹栈符号”时,弹出节点栈栈顶结点,并判断是否应将其接入语法分析树中。
递归下降语法分析
递归下降语法分析器从语法的最高层开始,逐层向下分析。在分析过程中,如果当前的符号是非终结符,则递归调用该非终结符所对应的子程序;如果当前的符号是终结符,则匹配当前的符号,生成相应结点连接到语法树,并将输入指针指向下一个符号。在每个非终结符的处理函数中,根据其一个或多个产生式的Predict集,选择相应的处理方法,因此我们的递归下降语法分析器结构如下:

实现该种方法的语法分析程序时,关键在于为各个非终结符编写处理程序,从而通过一次完整的递归调用完成语法分析工作。该种语法分析方法虽然逻辑简单 但代码工作量较大,且存在规律性,因此我们仍然使用Python代码自动生成所有非终结符的处理程序,其大致思路为:
按照所有以该非终极符为左部的产生式,及其相应的 Predict集,按产生式右部顺序进行终极符号匹配或非终极符程序调用,并在无法选择产生式时进行报错。
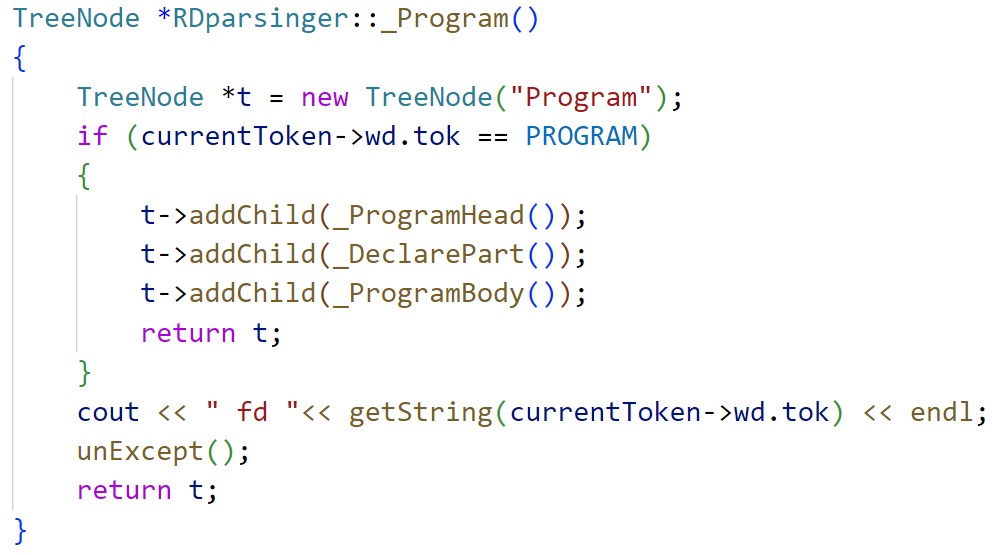
同时为避免函数名称标识符与枚举类型标识符重复,我们用“_非终极符名称”为函数命名,并且严格按照predict集合进行推导,即使非终结符只有一条产生式,也仍然判断待处理Token序列头是否属于其predict集合,使得分析过程更加严谨,如非终极符Program的处理程序为:
语法分析部分总结
在该部分,我们仅从产生式出发,求解了SNL语言语法分析中各个产生式的predict集,并实现了两种面向对象、可读性强、代码结构统一的语法分析器.,过程中我们使用Python代码简化工作量,最终达到了
800行c语言代码 + 250行 python代码 -> 2500行语法分析程序(c语言)
的效果。更重要的是实现了通用的C语言语法分析程序生成程序,该程序以一门特定编程语言的产生式集合作为输入,自动生成其相应的递归下降语法分析程序和LL(1)语法分析程序。